NOIP2011 普及组
T1:数字反转
题目描述
给定一个整数,请将该数各个位上数字反转得到一个新数。新数也应满足整数的常见形式,即除非给定的原数为零,否则反转后得到的新数的最高位数字不应为零(参见样例2)。
输入格式
一个整数
输出格式
一个整数,表示反转后的新数。
输入输出样例
输入样例 #1
123
输出样例 #1
321
输入样例 #2
-380
输出样例 #2
-83
说明/提示
数据范围
。
noip2011普及组第一题
题解:
本题考查的是字符串问题。把数字以字符串类型读入后,先判断是否为负数,是负数的话输出负号。然后,设置一个 类型的变量来查看前导零是否处理完毕,如果处理完毕的话那么便从后向前输出就可以了。
#include <cstring>
#include <iostream>
using namespace std;
int main() {
string n;
cin >> n;
if (n[0] == '-')
cout << "-";
bool zero = true; //处理前导0
for (long long i = n.length() - 1; i >= 1; i--)
if (n[i] - '0' != 0 || zero == false) {
cout << n[i];
zero = false;
}
if (n[0] != '-')
cout << n[0];
return 0;
}
T2:统计单词数
题目描述
一般的文本编辑器都有查找单词的功能,该功能可以快速定位特定单词在文章中的位置,有的还能统计出特定单词在文章中出现的次数。
现在,请你编程实现这一功能,具体要求是:给定一个单词,请你输出它在给定的文章中出现的次数和第一次出现的位置。注意:匹配单词时,不区分大小写,但要求完全匹配,即给定单词必须与文章中的某一独立单词在不区分大小写的情况下完全相同(参见样例1 ),如果给定单词仅是文章中某一单词的一部分则不算匹配(参见样例2 )。
输入格式
共行。
第行为一个字符串,其中只含字母,表示给定单词;
第行为一个字符串,其中只可能包含字母和空格,表示给定的文章。
输出格式
一行,如果在文章中找到给定单词则输出两个整数,两个整数之间用一个空格隔开,分别是单词在文章中出现的次数和第一次出现的位置(即在文章中第一次出现时,单词首字母在文章中的位置,位置从 开始);如果单词在文章中没有出现,则直接输出一个整数。
输入输出样例
输入样例 #1
To
to be or not to be is a question
输出样例 #1
2 0
输入样例 #2
to
Did the Ottoman Empire lose its power at that time
输出样例 #2
-1
说明/提示
数据范围
单词长度。
文章长度。
noip2011普及组第2题
题解:
同第一题一样,本题还是一个字符串问题。
我们依次读入给定单词与给定的文章,然后从给定的文章中查找有没有给定的单词。我们用 变量指向文章的位置,用 变量指向给定单词的位置,用 变量表示文章中的某一个单词与给定单词是否一样。那么,当找到文章中的空格时,代表文章中一个单词的结束,因此,我们将 与 清零继续寻找。
对于正常的字母,我们将它与给定单词中的相对应字母进行比较,如若是同一个字母的话那么 便加一。
如果 的长度与给定单词的长度相等时,我们便来查看文章的下一个字符是否为空格,是空格的话那么答案便加一,最后,输出答案就可以了!
#include <cstdio>
#include <cstring>
#include <iostream>
using namespace std;
int main() {
string want, article;
getline(cin, want);
getline(cin, article);
int j = 0; //存储该第几个want了
int same = 0, ans = 0;
long long first = -1;
for (long long i = 0; i < article.length(); i++) {
if (article[i] == ' ') {
same = 0;
j = 0;
} else {
if ((article[i] - 32) == want[j] || (article[i] + 32) == want[j] || article[i] == want[j]) {
same++;
j++;
} else {
j = 0;
same = 0;
for (; i < article.length(); i++)
if (article[i] == ' ')
break;
}
}
if (same == want.length() && article[i + 1] == ' ') {
if (first == -1)
first = i - want.length() + 1;
ans++;
}
}
if (ans == 0)
cout << -1 << endl;
else
cout << ans << " " << first << endl;
return 0;
}
T3:瑞士轮
题目背景
在双人对决的竞技性比赛,如乒乓球、羽毛球、国际象棋中,最常见的赛制是淘汰赛和循环赛。前者的特点是比赛场数少,每场都紧张刺激,但偶然性较高。后者的特点是较为公平,偶然性较低,但比赛过程往往十分冗长。
本题中介绍的瑞士轮赛制,因最早使用于年在瑞士举办的国际象棋比赛而得名。它可以看作是淘汰赛与循环赛的折中,既保证了比赛的稳定性,又能使赛程不至于过长。
题目描述
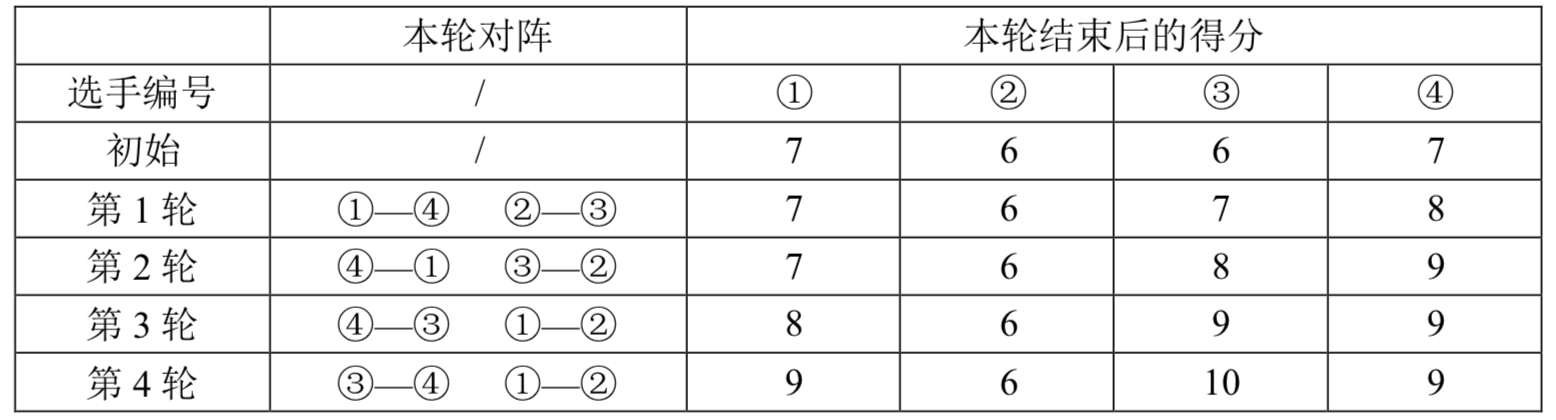
名编号为 的选手共进行R 轮比赛。每轮比赛开始前,以及所有比赛结束后,都会按照总分从高到低对选手进行一次排名。选手的总分为第一轮开始前的初始分数加上已参加过的所有比赛的得分和。总分相同的,约定编号较小的选手排名靠前。
每轮比赛的对阵安排与该轮比赛开始前的排名有关:第 名和第 名、第 名和第 名、……、第名和第名、…… 、第名和第名,各进行一场比赛。每场比赛胜者得分,负者得 分。也就是说除了首轮以外,其它轮比赛的安排均不能事先确定,而是要取决于选手在之前比赛中的表现。
现给定每个选手的初始分数及其实力值,试计算在R 轮比赛过后,排名第 的选手编号是多少。我们假设选手的实力值两两不同,且每场比赛中实力值较高的总能获胜。
输入格式
第一行是三个正整数每两个数之间用一个空格隔开,表示有 名选手、 轮比赛,以及我们关心的名次 。
第一行是三个正整数,每两个数之间用一个空格隔开,表示有 名选手、 轮比赛,以及我们关心的名次 。 第二行是 个非负整数,每两个数之间用一个空格隔开,其中表示编号为 的选手的初始分数。 第三行是 个正整数,每两个数之间用一个空格隔开,其中 表示编号为 的选手的实力值。
输出格式
一个整数,即 轮比赛结束后,排名第 的选手的编号。
输入输出样例
输入样例 #1
2 4 2
7 6 6 7
10 5 20 15
输出样例 #1
1
说明/提示
【样例解释】
【数据范围】
对于的数据,;
对于的数据,;
对于的数据,。
noip2011普及组第3题
题解:
看到本题,我们首先想到的肯定就是排序了呗!每次按得分从高到低进行排序,然后两两一组进行比拼。如果用快速排序的话,复杂度一般为 ,再加上两两比较的过程,肯定会超时。
为什么快排会超时呢?快排每次都将得分看成一个无序的数组进行排序。而实际上,我们只需要排一次序之后,得分便基本上变成了一个有序序列。为什么呢?排过一次序之后,每两个相邻得分之间便肯定有一个得分会 ,有一个得分不变。因此,它便是一个基本有序的序列。
那么,又如何再对这个基本有序的序列进行排序呢?这就很符合 归并排序 合并的性质。
归并排序的合并流程是什么呢?
如图,我们有两个递减序列 与 。

我们设置一个数组 用来存储合并之后的有序数组。我们设置一个变量 来指向 数组中的第一个元素 ,设置 来指向 数组中的第一个元素 。我们比较 与 的大小,将 放入 中,;再比较当前 , 指向的元素 与 ,将 放入 中,;再比较当前 , 指向的元素与 ,将 放入 中,...... 依次进行下去,直到两个数组中的所有元素都被放入 数组后停止合并。这样,我们本便可以得到一个有序数组 了。我们再两两一组进行比拼,实力值高的得分便 。
归并排序合并过程要求 、 两个数组必须是有序的。因此,我们先将初始得分 一遍,然后进行 轮拆分与合并。因为 序列基本有序,所以,我们便比较相邻两个实力值,实力值高的放在 数组,实力值低的放在 数组,这样就可以保证 、 两数组有序了。然后再按照上述的合并过程进行合并。在 轮之后,输出排名为 的选手的编号就可以辣!
#include <iostream>
#include <algorithm>
using namespace std;
struct node {
int number, score, w;
} N[200001], A[100001], B[100001];
bool cmp (node x, node y) { //结构体排序
if (x.score == y.score)
return x.number < y.number;
return x.score > y.score;
}
void PUT (int which, int p, int i) {
if (which == 1) {
N[p].number = A[i].number;
N[p].score = A[i].score;
N[p].w = A[i].w;
} else {
N[p].number = B[i].number;
N[p].score = B[i].score;
N[p].w = B[i].w;
}
}
void Merge(int n) { //按分数进行归并
int p = 1;
int i = 1, j = 1;
while(i <= n && j <= n) {
if (A[i].score > B[j].score || (A[i].score == B[j].score && A[i].number < B[j].number)) {
PUT(1, p, i);
p++;
i++;
} else {
PUT(2, p, j);
p++;
j++;
}
}
for (; i <= n; i++) {
PUT(1, p, i);
p++;
}
for (; j <= n; j++) {
PUT(2, p, j);
p++;
}
}
int main() {
int n, r, q;
cin >> n >> r >> q;
for (int i = 1; i <= 2 * n; i++) {
N[i].number = i;
cin >> N[i].score;
}
for (int i = 1; i <= 2 * n; i++)
cin >> N[i].w;
sort(N + 1, N + 1 + 2 * n, cmp);
for (int v = 1; v <= r; v++) {
for (int i = 2; i <= 2 * n; i += 2)
if (N[i].w > N[i - 1].w) { //保证A、B两个序列都是递减的
A[i / 2].number = N[i].number;
A[i / 2].score = N[i].score + 1;
A[i / 2].w = N[i].w;
B[i / 2].number = N[i - 1].number;
B[i / 2].score = N[i - 1].score;
B[i / 2].w = N[i - 1].w;
} else if (N[i - 1].w > N[i].w) {
A[i / 2].number = N[i - 1].number;
A[i / 2].score = N[i - 1].score + 1;
A[i / 2].w = N[i - 1].w;
B[i / 2].number = N[i].number;
B[i / 2].score = N[i].score;
B[i / 2].w = N[i].w;
}
Merge(n);
}
cout << N[q].number << endl;
return 0;
}
T4:表达式的值
题目描述
对于 位二进制变量定义两种运算:
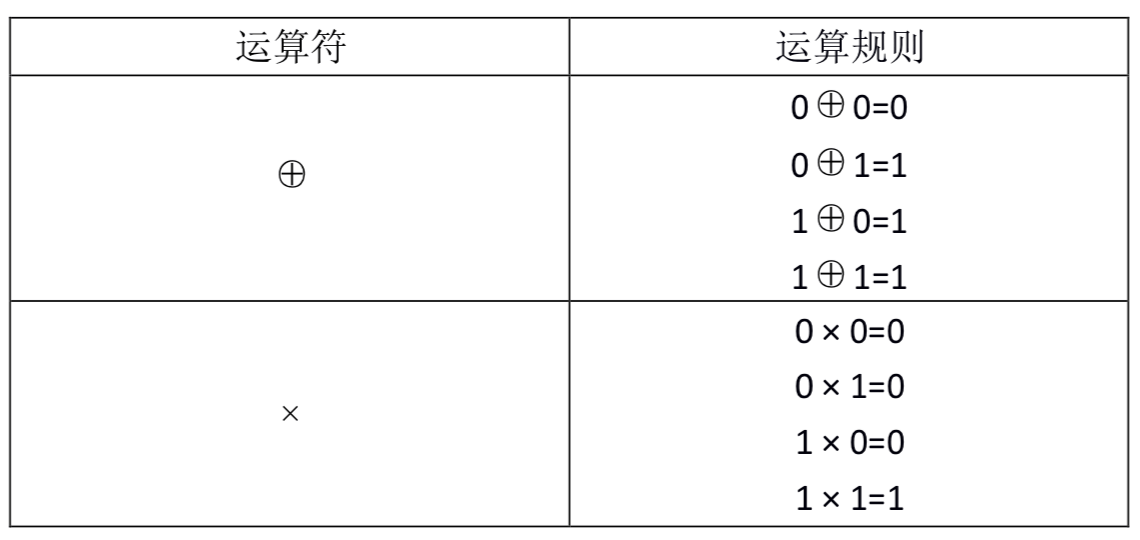
运算的优先级是:
- 先计算括号内的,再计算括号外的。
- “× ”运算优先于“⊕”运算,即计算表达式时,先计算× 运算,再计算⊕运算。例如:计算表达式A⊕B × C时,先计算 B × C,其结果再与 A 做⊕运算。
现给定一个未完成的表达式,例如_+(_*_),请你在横线处填入数字或者 ,请问有多少种填法可以使得表达式的值为。
输入格式
共 行。 第 行为一个整数 ,表示给定的表达式中除去横线外的运算符和括号的个数。 第 行为一个字符串包含 个字符,其中只包含’(’、’)’、’+’、’*’这 种字符,其中’(’、’)’是左右括号,’+’、’*’分别表示前面定义的运算符“⊕”和“×”。这行字符按顺序给出了给定表达式中除去变量外的运算符和括号。
输出格式
共 行。包含一个整数,即所有的方案数。注意:这个数可能会很大,请输出方案数对取模后的结果。
输入输出样例
输入样例 #1
2 4 2
7 6 6 7
10 5 20 15
输出样例 #1
1
说明/提示
【输入输出样例说明】
给定的表达式包括横线字符之后为:_+(_*_) 在横线位置填入(0 、0 、0) 、(0 、1 、0) 、(0 、0 、1) 时,表达式的值均为0 ,所以共有3种填法。
【数据范围】
对于 的数据有。 对于 的数据有 。 对于 的数据有 。 对于的数据有。 对于 的数据输入表达式中不含括号。
noip2011普及组第4题
题解:
如果带有 '(' 、 ')' 的话,无疑,计算会变得十分困难。因此,我们要将正常顺序的表达式去掉括号。这就是中缀表达式转后缀表达式。
中缀表达式转后缀表达式是什么呢?
假设我们需要转化的中缀表达式为:
a + b * c + ( d * e + f ) * g
首先,我们将中缀表达式按运算顺序全部加上括号,得到:
**(((a + (b * c)) + ((( d * e) + f ) * g))**
然后将每一个运算符号移到对应的括号后面,得到:
**(((a(bc))+ (((de) * f )+ g))+**
去掉括号,得到:
abc *+de*f+g*+
至此,中缀表达式便转成了后缀表达式。
那么,用计算机语言是如何实现的呢?
用 存储后缀表达式。读取完中缀表达式之后,从左到右扫描每一个字符,如果扫描到的字符是操作数的话,就将这些操作数存入 数组。
我们设置一个栈临时存放符号,当读取到其他字符时,分三种情况:
- 如果是左括号 '(' 或乘号 '*' 的话,直接进栈。
- 如果是加号 '+' 的话,那么便从栈中一直弹出乘号到 数组,直到栈顶元素不是乘号时停止弹出,将加号放入栈中。
- 如果是右括号 ')' 的话,那么便从栈中依次弹出符号到 数组,直到栈顶元素为左括号停止弹出,删除左括号。
- 如果不是左括号 '(' 或右括号 ')' 的话,我们便将 '_' 字符放入 数组,表示这个位置应该放数字。
这样,便实现了从中缀表达式转为后缀表达式。
然后,我们设置 数组与 数组,用来表示当前这个数字以及它前面一共有多少种构成 与非 的方案。用 变量指向对应的数字。从前往后进行扫描,当扫描到字符时, ,并进行如下判断:
- 当扫描到后缀表达式的符号为加号 '+' 时,我们可以想,一个非零数加一个零为非零数,一个零加一个零为零。所以,当前数字及其前面不为 的方案总数为: ,为 的方案总数为: 。
- 当扫描到后缀表达式的符号为乘号 '*' 时,我们可以想,一个非零数乘上一个零为零,一个非零数乘上一个非零数零为非零数。所以,当前数字及其前面为 的方案总数为:,不为 的方案总数为:。
最后,输出 就可以辣!
#include <iostream>
#define MOD 10007
using namespace std;
char a[100001], b[100001]; //a表示中缀表达式,b代表栈
char expression[100001]; //后缀表达式
int k = 2;
int zero[100001], other[100001];
int cnt;
void change (int l) { //中缀表达式 ---> 后缀表达式
expression[1] = '_';
int top = 1;
for (int i = 1; i <= l; i++) {
if (a[i] == '(' || a[i] == '*') {
b[top] = a[i]; //左括号、乘号直接进栈
top++;
}
if (a[i] == '+') {
top--;
while (b[top] == '*') {
expression[k] = b[top];
k++;
top--;
}
top++;
b[top] = '+';
top++;
}
if (a[i] == ')') {
top--;
while (b[top] != '(') {
expression[k] = b[top];
k++;
top--;
}
}
if (a[i] != '(' && a[i] != ')') {
expression[k] = '_';
k++;
}
}
top--;
for (; top >= 1; top--) {
if (b[top] != '(') {
cnt++;
expression[k] = b[top];
k++;
}
}
}
int main() {
int l;
cin >> l;
for (int i = 1; i <= l; i++)
cin >> a[i];
change (l);
int num = 0;
for (int i = 1; i < k; i++) {
if (expression[i] == '_') {
num++;
zero[num] = 1;
other[num] = 1;
} else if (expression[i] == '+') {
num--;
other[num] = (other[num] * zero[num + 1] % MOD + other[num + 1] * zero[num] % MOD + other[num] * other[num + 1] % MOD) % MOD;
zero[num] = (zero[num] * zero[num + 1]) % MOD;
} else if (expression[i] == '*') {
num--;
zero[num] = (other[num] * zero[num + 1] % MOD + other[num + 1] * zero[num] % MOD + zero[num] * zero[num + 1] % MOD) % MOD;
other[num] = (other[num] * other[num + 1]) % MOD;
}
}
cout << zero[1] << endl;
return 0;
}